Le terme NoOps (No Operations), littéralement l’absence de personnel d’exploitation, a été inventé par Forrester qui le définit comme “l’objectif d’automatisation complète du déploiement, de la surveillance et de l’administration des applications, ainsi que de l’infrastructure sur laquelle elles s’exécutent”.
L’objectif du NoOps ou (Dev)NoOps est donc de mettre en place process et outils afin que les déploiements d’applications et d’infrastructures soient automatisés par design, sans intervention humaine.
La mort du DevOps ?
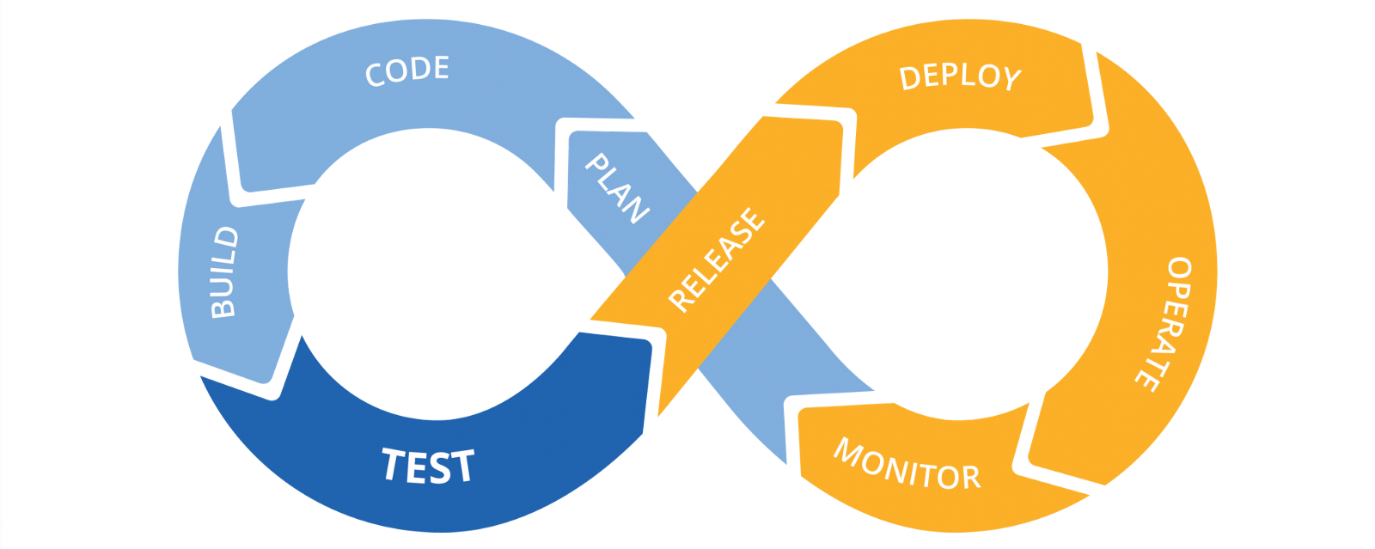
Le concept NoOps va t’il tuer le DevOps, concept rapprochant les équipes de Développements et Opérations dans lequel les membres de chaque équipe peuvent endosser certaines responsabilités de l’autre, en poussant à son paroxysme le concept de CI/CD ?
You build it, you run it !
Intégration Continue (Continuous Integration, CI)
La CI, directement dérivée du concept de programmation extrême (eXtreme Programming, XP), consiste à consigner et tester les modifications fréquentes de code de plusieurs développeurs lors de la fusion dans un référentiel de versions de code.
La CI permet une intégration de code plus rapide car celui-ci est intégré à un rythme plus soutenu qu’avec d’autres approches de développement plus classiques, comme le modèle en cascade (Waterfall).
Chaque modification importante d’une équipe de développement déclenche la création d’un build afin de détecter au plus tôt les anomalies dans le cycle de développement à l’aide de tests unitaires et fonctionnels automatisés.
Les anomalies sont détectées plus facilement et rapidement car il y a de fortes chances qu’un problème se trouve dans le dernier lot de code fusionné.
Les retours en arrière (rollback) sont plus simples car les modifications isolées peuvent être annulées dans le référentiel de code.
Livraison Continue (Continuous Delivery, CD)
La livraison continue est une extension naturelle de l’intégration continue permettant de publier rapidement de nouveaux changements applicatifs.
Ce processus permet de créer, tester et déployer plus rapidement des logiciels en privilégiant des mises à jour incrémentielles au lieu de refontes complètes.
Elle évite à l’équipe de développement de passer du temps à préparer la publication du code et regrouper de nombreuses petites modifications.
L’équipe met à jour le code en continu et le publie par petits incréments dans un environnement de test afin de vérifier tous les aspects opérationnels, logique des règles métier comme les éventuels problèmes de performances avant la mise en production.
Cela signifie qu’en plus d’avoir automatisé les tests, le processus de publication a également été automatisé afin de déployer une nouvelle version applicative à tout moment en cliquant sur un bouton.
La stratégie de déploiement bleu/vert (Blue Green Deployment), également appelée déploiement A/B, couramment utilisée en CD, nécessite deux environnements matériels identiques et configurés exactement de la même façon.
L’un de ces deux environnements est mis à la disposition des utilisateurs, tandis que l’autre est utilisé pour le déploiement d’un nouveau code et est soumis aux tests.
Lorsque le code publié est validé par les tests, les sources de trafic des environnements peuvent être inversées (swap) et le nouveau code devient à son tour accessible aux utilisateurs.
Si un problème est découvert après ce transfert, il est possible de ré-inverser les environnements et rediriger de nouveau le trafic vers l’environnement qui était fiable le temps de trouver une solution.
Déploiement Continu (Continuous Deployment, CD)
Dans la livraison continue, le code passe par différentes étapes de préparation à sa publication en production, mais il n’est pas automatiquement déployé.
Les modifications du code doivent d’abord être soumises à des tests d’acceptation (User Acceptance Testing, UAT) et une assurance qualité (Quality Assurance, QA) manuels.
Le déploiement continu va plus loin que la livraison continue : le code est automatiquement testé, validé et mis en production avec une surveillance des problèmes susceptibles de nécessiter un retour en arrière sans intervention humaine.
Seul un test automatisé en échec empêchera le déploiement d’une nouvelle version applicative en production.

CI et CD sont souvent associées sous l’appellation de pipeline CI/CD, chemin complet de déploiement d’un artefact.
Les étapes d’un pipeline de CI sont :
- Contrôle de versions : code publié (commit) dans référentiel de code (GitHub, BitBucket, Subversion, etc.)
- Build : compilation du code et exécution des tests unitaires sur un serveur de CI
- Tests d’intégration
- Dépôt des artefacts générés (packages, images, etc.)
Le pipeline CI/CD est complet lorsque un artefact est déployé sur un environnement de test pour validation par l’utilisateur ou en production.
Dans le concept CI/CD et l’approche DevOps, il est ainsi possible de livrer fréquemment aux utilisateurs de nouvelles fonctionnalités en réduisant au maximum le nombre d’incidents, la mise en production devenant quasiment un “non événement”.
En cas d’incident de production, il est possible de livrer rapidement une précédente version ou une nouvelle version corrective afin de résoudre le problème et mener les actions nécessaires pour que celui-ci ne se reproduise plus.
Evolution vers le (Dev)NoOps
Revenons au concept NoOps dans lequel l’infrastructure doit également être déployée automatiquement sans intervention humaine.
Le concept de CI/CD appliqué aux logiciels doit également s’appliquer aux infrastructures sur lesquelles ces logiciels s’exécutent.
L’Infrastructure as Code (IaC) permet d’automatiser la gestion, l’approvisionnement et la mise à l’échelle de l’Infrastructure informatique (espace de stockage, puissance de calcul, réseau, etc.) par code.
L’IaC repose sur des outils (ex. Terraform) offrant une abstraction de haut niveau des ressources d’infrastructure en utilisant une syntaxe déclarative qui définit un état final souhaité au lieu d’une syntaxe impérative qui décrit une série d’actions pour arriver à une finalité.
La séparation de la configuration du code et de sa variabilisation permettent de maximiser l’usage d’un template dynamique pour de multiples environnements et ainsi fournir une infrastructure reproductible, standardisée et extensible.
Si l’on considère que les scripts d’automatisation sont du code, celui-ci diffère du code produit par les équipes de développement dont l’objectif premier est de fournir de nouvelles fonctionnalités aux utilisateurs.
Le métier des Ops n’est pas compromis, il évolue dans un écosystème agile avec l’acquisition de nouvelles compétences pour maintenir et documenter les scripts d’automatisation, librairies et outils, tâches qui leur étaient déjà en partie dévolues dans l’approche DevOps.
Notre vision
Le NoOps ayant pour pilier l’automatisation des nouvelles productions modernes et remplaçant le DevOps ne sera pas applicable dans toutes les organisations.
En effet, la mise en oeuvre d’une approche DevOps nécessitant de nouveaux processus opérationnels et la mise en place de nouveaux outils impacte déjà fortement les organisations et s’applique plus facilement aux applications modernes et Cloud native qu’aux systèmes plus anciens (applications dites Legacy) cohabitant dans un SI.
Le NoOps n’est-il pas finalement du DevOps “parfaitement” appliqué aux infrastructures et logiciels et complètement automatisé ?
Ken Corless, ex Deloitte’s principal et Deloitte’s Cloud Practice CTO, décrit NoOps en tant que “pinnacle of the DevOps mountain” (sommet de la montagne DevOps).
Le NoOps, comme le DevOps précédemment, réinvente le métier des Ops en les recentrant sur leur coeur de métier (engagement de service vis à vis du client, SLA, opérer 24h sur 24 une plateforme de production, supervision) et permet aux développeurs de ne plus tenir compte des aspects liés aux ressources d’infrastructure.
Les facteurs de réussite de la mise en oeuvre d’une approche totalement NoOps sont pour nous les suivants :
⦁ Applications Cloud native (PaaS, Serverless, conteneurs ou architecture orientée micro-service) respectant la méthodologie Twelve-Factor App,
⦁ Approche DevOps déjà mise en oeuvre,
⦁ Pipelines CI/CD robustes,
⦁ Des Dev et Ops qui évoluent, épaulés de nouveaux profils d’architectes et spécialistes Cloud pour penser et mettre en oeuvre les architectures de demain (certains se cachent ici par exemple) !
Merci pour cette article clair.
Sur le papier ça semble logique et indispensable de mettre en place ces mécanismes, mais cela nécessite un changement de mentalité dans les équipes Dev et surtout Ops pour sortir des guerres de pouvoirs et des périmètres hautement silotés.