Il y a quelques semaines, nous avions parlé du Machine Learning. Cette fois-ci, continuons à essayer de démystifier des concepts passionnants et obscurs avec le Deep Learning.
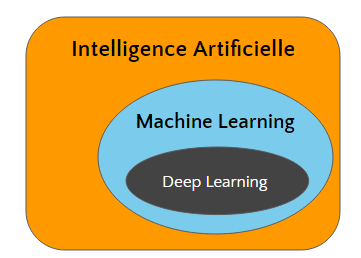
Nous avons vu que le Machine Learning est un domaine de l’intelligence artificielle qui vise à étudier comment des algorithmes peuvent apprendre en étudiant des exemples.
Le Deep Learning est une méthode particulière d’apprentissage, qui ouvre de nouvelles possibilités.
Des exemples connus et visibles tirant partie de ces procédés de Deep Learning sont AlphaGo qui s’est imposé face aux champions du jeu de Go, DeepDream de Google ou même Watson d’IBM.
Afin de qualifier le Deep Learning un rapide rappel sur le Machine Learning s’impose.
Le Machine Learning
Le Machine Learning vise à entraîner un algorithme en se basant sur des exemples, avec pour objectif la construction d’un modèle prédictif. Le but est d’être capable de déterminer ce qui lie une sortie à une entrée.
Nous avons pris un exemple simple basé sur les données suivantes :
Notre objectif était de déterminer la fonction ou l’algorithme qui transforme les nombres en entrées en ceux en sortie.
Pour cela le Machine Learning va étudier les exemples fournis, puis essayer de déterminer l’algorithme de transformation. Cette phase s’appelle l’apprentissage.
C’est là que l’algorithme se sert des exemples fournis pour trouver un lien entre les données en sorties et les données en entrées. Ainsi il sera capable, peu importe le nombre en entrée, de déterminer le nombre en sortie.
Pour parvenir à cet objectif, l’algorithme va définir une fonction f(x)=aX, et faire varier a, jusqu’à ce qu’il trouve la bonne valeur. “a” est une caractéristique permettant de déterminer la sortie en fonction de l’entrée. Ici c’est a =2, et donc la fonction liant les entrées aux sortie est Y = f(x) = 2x.
Ensuite il sera capable de déterminer quelle sera la sortie (Y) pour n’importe quelle valeur de X, même si cette valeur n’est pas présente dans les exemples utilisés pour l’apprentissage.
Cette deuxième phase, c’est la prédiction. Simplement, l’algorithme est maintenant capable de déterminer que si X = 5, Y= 10.
Dans notre article précédent, nous nous en étions arrêté là. Maintenant comment modéliser des problématiques plus compliquées avec des dizaines de caractéristiques comme “a” différentes ?
Les réseaux de neurones
Prenons un exemple concret et cherchons à construire un algorithme qui exprime le temps qu’il a fait dans une journée (beau temps ou mauvais temps).
 Pour cela, il faut lui fournir un certain nombre de paramètres en entrée :
Pour cela, il faut lui fournir un certain nombre de paramètres en entrée :
- La température
- L’hygrométrie
- La pression atmosphérique
- La vitesse du vent
Et lui donner des exemples pour s’entraîner.
Evidemment plus le nombre d’exemple sera grand et varié, plus l’entraînement permettra d’arriver à un modèle précis et pertinent. Ici il faudrait un grand nombre de cas exposés pour être capable de généraliser la subjectivité liée au beau temps ou au mauvais temps. Pour la simplicité de l’exemple, nous nous en tiendrons à ces quelques valeurs.
Au final, nous aurons un algorithme qui pourra déterminer pour n’importe quel ensemble de ces entrées (Température, pression, hygrométrie, vitesse du vent) s’il fait beau ou non.
Pour modéliser et appréhender cette relation complexe nous avons besoin d’un réseau de neurones.
Ce réseau de neurones aura deux couches (et sera donc extrêmement simple) :
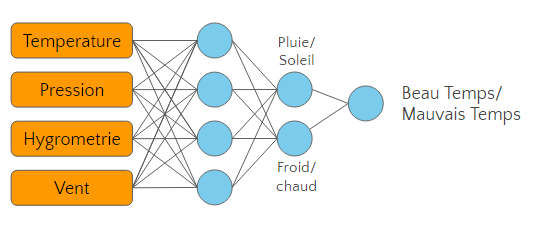
L’intérêt du réseau de neurones est de modéliser l’impact des différents facteurs et leur relation entre eux. Lorsque la complexité des facteurs est grande, plutôt que de les traiter tous ensemble, on décompose l’analyse en étapes, les plus petites possibles.
Chaque étape est représentée par un neurone. Un neurone reçoit un certain nombre d’informations, chacune pondérée (p), et renvoi une réponse binaire 0 ou 1.
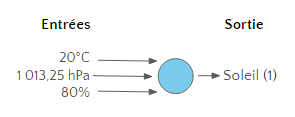
Ensuite cette réponse va venir alimenter le neurone suivant dans le réseau, qui lui-même produira une réponse binaire, et ainsi de suite jusqu’au dernier neurone du réseau.
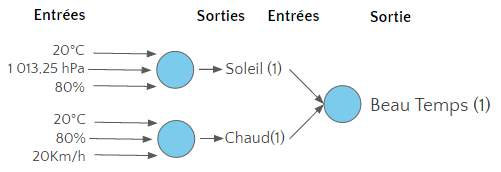
La sortie du dernier neurone du réseau représente la réponse que l’on cherche à obtenir.
Pour affiner ce modèle, on joue sur la pondération de chaque entrée et le seuil qui déclenche la sortie 0 ou la sortie 1.
Autrement dit, un neurone : est une fonction mathématique qui met en relation une entrée X et une sortie Y. L’importance de chaque critère d’entrée est pondéré par un coefficient “p”. Avec le seuil “s”, d’activation de la sortie (qui va définir à quel moment la sortie va afficher 0 ou 1, soleil ou pluie ici), ce sont les deux variables qui vont pouvoir évoluer pour affiner et donc entraîner notre réseau de neurone pendant la phase d’apprentissage.
Le réseau de neurones permet donc de traiter des cas complexes avec de multiples entrées. Toutefois que se passe t’il lorsque les entrées sont encore plus nombreuses ?
Machine Learning et concepts abstraits
Dans le cas d’une image où l’objectif est d’identifier automatiquement ce qu’elle représente, les entrées seraient les pixels. Une image de 300x300px, représente 90 000 pixels et donc 90 000 valeurs en entrées potentielles. Tout traiter dans un réseau de neurones traditionnel serait bien trop complexe, et ce dernier serait incapable d’intégrer les concepts nécessaires à l’abstraction de l’image pour en déduire quoi que ce soit.
Intuitivement, nous serions tentés de penser qu’il faut traiter l’image par groupe de pixels pour faire ressortir des arbres, des constructions, des personnages etc…
C’est exactement ce qu’il manque pour pouvoir traiter ces images : des caractéristiques représentatives qui vont représenter au final, les entrées à traiter par le réseau de neurones.
Dans ce cas un algorithme tiers (non lié au réseau de neurone ou au machine learning) identifiera des caractéristiques prédéfinies.
Par exemple, si l’on veut que l’algorithme soit capable de distinguer sur des photos les motos des voitures, les caractéristiques à identifier en amont seraient
- Nombre de roues
- Nombres de vitres
- La forme
- Présence d’un casque…
Une fois ces caractéristiques identifiées il “suffit” de les passer au réseau de neurones qui, comme pour l’exemple de la météo, les traitera à partir d’exemples et identifiera une logique pour distinguer moto et voitures.
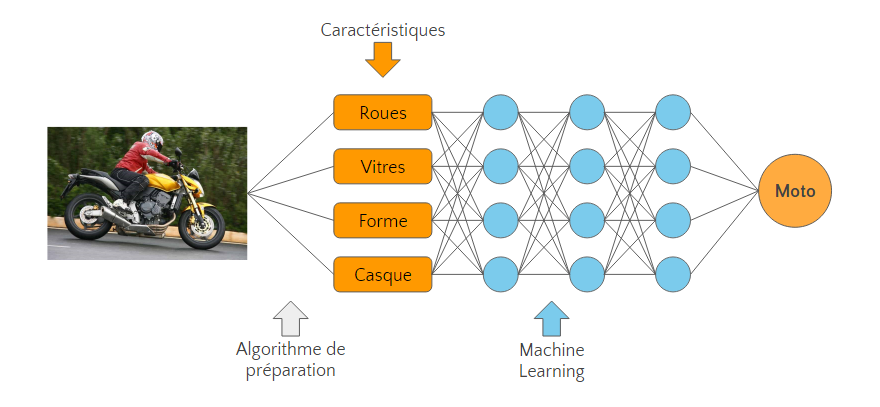
Cette solution nous laisse néanmoins avec deux problèmes :
- Les performances de tels algorithmes sont loin d’être parfaites (15% d’erreurs)
- Les caractéristiques à identifier dépendent de l’expertise humaine. Que faire alors dans une situation où les caractéristiques distinctives d’une situation ne sont pas identifiables par l’homme ? Autrement dit lorsqu’on ne sait pas déterminer intuitivement le lien entre la sortie et l’entrée ?
Le Deep Learning
Le Deep Learning permet donc implicitement de répondre à des questions du type “que peut on déduire de ces données ?”
Ce qui rend le deep learning différent des méthodes de machines learning traditionnelles c’est que lors d’analyses complexes, les caractéristiques essentielles du traitement ne seront plus identifiées par un traitement humain dans algorithme préalable, mais directement par l’algorithme de Deep Learning.
En effet, si le réseau de neurones est suffisamment bien entraîné, il sera en mesure de construire lui-même ces caractéristiques, et sera donc capable d’identifier ce qu’il y a sur une image. Dans notre cas une moto ou une voiture, sans lui avoir transmis au préalable des informations sur ce qui caractérise une voiture ou une moto.
Pour ce faire, il construira à partir des exemples à disposition, ses propres caractéristiques (parfois similaires à celles qu’un humain aurait identifiées : Nombre de roues, Vitres, forme, casque…) et s’en servira pour analyser l’image et définir s’il s’agit d’une moto ou d’une voiture.
Pour parvenir à cela on utilisera un réseau de neurone profond (plusieurs couches), auquel, une fois entraîné, on passera directement l’image en entrée.

Pour résumer, lorsque les méthodes traditionnelles d’analyse d’images, résument au préalable l’image selon des caractéristiques définies par des experts, le Deep Learning construit lui-même ses caractéristiques d’analyse.
Le Deep Learning permet donc implicitement de répondre à des questions du type “que peut on déduire de ces données ?” et ainsi décrire des caractéristiques parfois cachées ou des relations entre des données souvent impossibles à identifier pour l’homme.
Nous disions plus tôt que passer des images sans les résumer à des réseaux de neurones serait trop complexe, et c’était le cas jusqu’en 2012 environ.
Même si leur origine remonte à aux années 90 avec Yann Le Cun, c’est donc au début des années 2010 avec les travaux de Geoffrey Hinton, que les algorithmes de Deep Learning ont commencé à démontrer leur efficacité.
Qu’est ce qui a changé ?
Les architectures des réseaux de neurones se sont améliorés et la puissance de calcul disponible a grimpée en flèche (grâce au Cloud notamment).
Mais la plus grande révolution, c’est la disponibilité des données. En effet, le grand enjeu pour le Deep Learning (encore plus que pour le machine learning) reste la capacité à être correctement entraîné et à avoir à disposition un nombre virtuellement infini d’exemples pour parfaire le modèle à construire.
Dans l’exemple précédent, pour qu’un tel réseau de Deep Learning fonctionne, il faut un nombre très élevé d’exemples de photos catégorisées représentant des voitures et des motos.
Cela est rendu possible par le partage de bases de données d’images catégories, qui permettent d’entraîner ces réseaux de neurones (Image Net, par exemple).
Et concrètement ?
Le plus intriguant (et le plus étonnant), reste la capacité à transformer les réseaux Deep Learning en modèle génératif.
Maintenant que le concept de Deep Learning est précisé, qu’est-ce que cela peut apporter ?
Evidemment, en allant dans le sens de l’exemple, analyser et décrire des images ou des vidéos pour faciliter des études ou automatiser des actions. Par exemple, pour un service client, être capable de préqualifier un défaut sur un produit, à partir de l’analyse automatique de la photo envoyée par le client insatisfait, en améliorant drastiquement le délai de traitement de sa demande.
Plus ambitieux, le Deep Learning permet d’établir des relations et d’identifier des causes qui restent indétectable par l’homme. On peut penser à un système de détection de fraudes avancées dans des contextes Big Data bancaires ou une optimisation de l’infrastructure de son informatique en fonction d’une demande qui serait anticipée par un réseau Deep Learning traitant en temps réel les actions des utilisateurs.
Enfin, le plus intriguant (et le plus étonnant), reste la capacité à transformer les réseaux Deep Learning en modèle génératif.
Le concept est simple : une fois le modèle entraîné (et donc les caractéristiques de traitement identifiées), on est en capacité d’inverser le processus en fournissant des entrées aux caractéristiques de traitement en sortie du réseau de neurones, pour obtenir une image originale.
Dans le cas de notre réseau qui permettait d’identifier motos et voitures, on peut imaginer lui fournir une information en entrée étant “Moto” et le voir créer des images originales de motos.
Une réponse à des pannes de créativité ou d’originalité dans le design des produits ?