Le serverless computing est un modèle de conception cloud natif basé sur une architecture ne nécessitant pas de gestion de serveurs pour créer et exécuter des applications.
Dans la lignée des services Cloud visant à faciliter le recours à des services innovants en limitant les investissements de capital, le serverless est un vrai choix stratégique, avec des enjeux liés à la stratégie fournisseur et au service rendu aux utilisateurs.
La fin des serveurs ?
Le terme “serverless” ne peut être littéralement traduit par “sans serveur” car les serveurs sont toujours présents dans le serverless computing !
Le nom “serverless” est utilisé car il décrit l’expérience de l’utilisateur final de ce type d’architecture, i.e. le développeur.
Dans ce paradigme, la gestion des ressources de calcul sous-jacentes est invisible pour un développeur car celui-ci n’interagit pas sur les serveurs.
Le serverless computing n’élimine donc pas les serveurs, mais vise à reléguer au second plan les questions liées aux serveurs, machines virtuelles et ressources de calcul nécessaires pour prendre en charge un très grand nombre de requêtes et d’événements car l’infrastructure est gérée par le fournisseur de services Cloud.
Serverless = BaaS + FaaS
Le terme “serverless” est souvent confondu à tort avec l’appellation FaaS (Function as a Service); or FaaS est seulement l’une des deux significations distinctes mais liées du serverless :
- BaaS (Backend as a Service) : les principaux services managés de Cloud computing, tels que les bases de données et le stockage, fournissent des APIs qui permettent aux applications clientes de se connecter directement à ces services.
- FaaS (Function as a service) : une fonction est un morceau de code déployé dans le cloud et exécuté dans un environnement complètement abstrait des serveurs exécutant le code.
Ces deux définitions sont liées par l’idée que les développeurs et le personnel DevOps n’ont pas besoin de déployer, configurer et gérer des serveurs.
C’est ainsi que le mouvement NoOps (No Operations) est né, concept selon lequel un environnement informatique a atteint un niveau d’automatisation et de virtualisation suffisant pour que plus aucune équipe interne ne soit nécessaire à l’administration de l’infrastructure logicielle.
Zoom sur le FaaS
Les plateformes FaaS des fournisseurs de services Cloud (Microsoft Azure Functions, AWS Lambda, Google Cloud Functions, IBM Cloud Functions, etc.) permettent d’exécuter uniquement à la demande du code ou un conteneur.
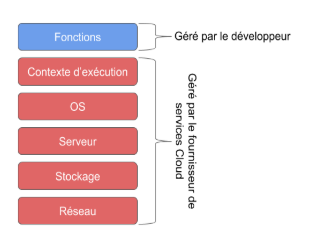
Les ressources de calcul sont allouées et mises à l’échelle de façon dynamique en fonction du trafic et du nombre de demandes (requêtes et évènements), sans que le développeur n’ait à effectuer de configuration.
Tous les fournisseurs partagent les limites maximales de leur plateformes FaaS : durée du délai d’expiration, mémoire, nombre d’appels par minute, taille des requêtes, stockage, etc.
Ces facteurs déterminants doivent être pris en compte lors du choix d’une architecture de type serverless ou non.
Comparatif des durées maximales du délai d’expiration :
| Function as a Service | Délai d’expiration max. (min) |
| Google Cloud Functions | 9 |
| Microsoft Azure Functions | 10 |
| IBM Cloud Functions | 10 |
| AWS Lambda | 15 |
Les fonctions sont exécutées par un déclencheur externe, une requête HTTP ou un message arrivant sur une file d’attente, permettant la mise en place d’un pattern d’architecture basé sur les événements : Event-Driven Architecture (EDA), que l’on abordera prochainement dans l’un de nos articles.
Avantages
Les modèles serverless redonnent une certaine autonomie aux développeurs, leur permettant ainsi de se concentrer sur le code et la logique métier et non sur l’infrastructure.
La tarification est effectuée à la demande et à la durée d’exécution, les utilisateurs ne paient que les ressources consommées, jamais le temps d’inactivité ou d’interruption des services.
Le serverless computing peut être à la fois plus rapide et plus économique que d’autres ressources de calcul pour des charges de travail nécessitant des traitements en parallèle.
Inconvénients
Les avantages en termes de coût du serverless computing ne sont plus pertinents pour des traitements de longue durée et la gestion d’un environnement serveur traditionnel peut s’avérer plus simple et plus rentable.
Les architectures serverless conçues pour tirer avantage au maximum des services cloud natifs et managés d’un fournisseur (BaaS) peuvent représenter un avantage pour les clients de ces fournisseurs mais ce modèle peut entraîner un phénomène de vendor lock-in pour d’autres entreprises clientes, qui souhaitent se protéger de la pression fournisseur. En effet, comme ces services tirent partie de la valeur ajoutée particulière du fournisseur, le recours au serverless augmente par définition l’adhérence à celui-ci. Le choix du serverless est donc un vrai engagement avec un fournisseur, et il faut s’assurer des possibilités de portabilité avant de s’engager.
Le serverless est avant tout une réponse ponctuelle et localisée à un besoin standardisé de calcul; il s’agit donc d’une opération temporaire, avec une allocation des ressources temporaires et à la demande.
Ainsi, les modèles d’architectures serverless, qui renoncent aux processus de longue durée au profit de l’allocation de ressources et de leur mise à l’échelle à la demande, peuvent être confrontés au phénomène de démarrage “à froid”.
En effet, une fonction qui n’a pas été appelée récemment entraîne une latence supplémentaire, généralement de l’ordre de quelques secondes, due à l’allocation et à la préparation de l’environnement lors de sa prochaine exécution.
Pour certaines applications, ce délai de démarrage n’a pas d’impact mais pour une application financière à faible temps de latence par exemple, ce délai ne pourrait être acceptable.
Cas d’utilisations
Les architectures serverless sont les plus appropriées pour les usages liés aux microservices, au traitement des données et des événements et aux objets connectés (IoT).
En effet, ces cas demandent de réaliser des actions simples, unitaires, relativement rapidement, mais de façon répétée; il s’agit donc d’usages où il n’est pas nécessaire de mobiliser en permanence une puissance de calcul qui s’avère inutilement puissante pour traiter ces usages.
Le cas d’utilisation le plus courant du serverless est l’architecture en microservices.
Une architecture de microservices se compose d’un ensemble de petits services autonomes implémentant chacun une fonctionnalité unique et communiquant les uns avec les autres via des APIs.
Bien que les microservices puissent être implémentés à l’aide de services PaaS ou de conteneurs, le serverless, compte tenu de ses attributs, est une excellente solution pour exécuter une petite quantité de code dédié à une seule fonctionnalité.
Une API publiée par une passerelle d’API Management peut ainsi être un microservice déployé sur une “fonction” (FaaS) accédant à des données stockées dans un service managé (BaaS), tel une base de données.
Le serverless est aussi adapté au traitement des données de type texte structuré, audio, image et vidéo autour de certaines tâches incluant :
- Enrichissement, transformation et validation des données,
- Traitement de fichiers PDF,
- Normalisation audio,
- Reconnaissance optique de caractères (OCR),
- Transcodage vidéo.
Ces tâches, spécifiques et unitaires, ne demandent pas de calculs supplémentaires au delà de la fonction appelée. On retrouve donc les cas où le serverless délivre une valeur ajoutée particulièrement importante.
Les modèles serverless sont également souvent associés aux services d’analyse de données en temps réel et en continu pour l’ingestion de flux de données de sources diverses :
- Capteurs IoT,
- Journaux d’événements techniques et fonctionnels (logs),
- Données de marchés financiers.
Dans ce contexte, ces modèles serverless sont déclenchés par des messages ou événements d’une file d’attente.
En bref
Le serverless ne marque donc pas la fin des serveurs. Il s’agit au contraire d’une ressource de plus pour les architectes afin d’optimiser la plateforme pour répondre aux enjeux de l’usage à adresser, et d’une possibilité offerte aux développeurs de gagner du temps dans la conception d’une application pour un usage ponctuel.
Le recours au serverless est conditionné à une stratégie fournisseur qui pourra s’accommoder d’une adhérence fournisseur plus forte, ainsi qu’à des impératifs liés au service partiellement maîtrisés (au niveau de la portabilité et de la maîtrise de l’environnement notamment).
[/fusion_text][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container]